Anyone who has stared at the flow matching path , with being sampled image and being sampled noise, can see that the path from an individual sampled data point to noise is a straight line and thus has constant velocity. If this is the case, then why, at inference time, can we not simply convert noise into image in one step?
 (image from 1)
(image from 1)
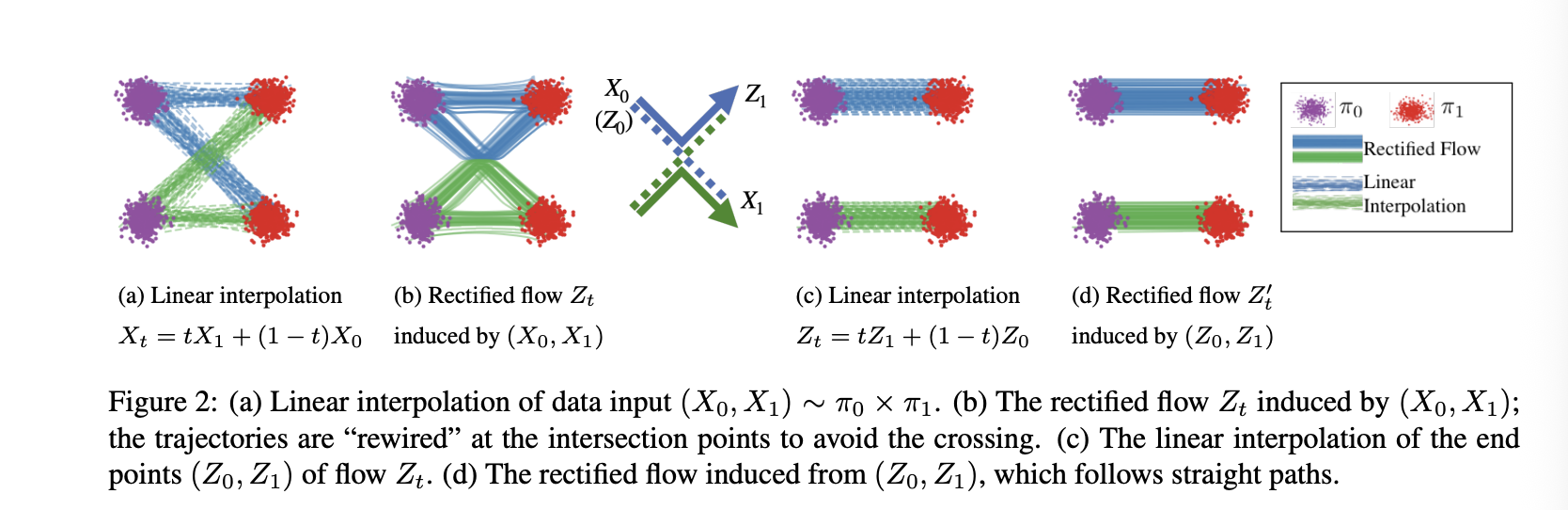
The answer is that the trained flow model predicts the average velocity of all of these paths. Since the noise and image anchors reside in various locations in Euclidean space, vectors representing transport paths are going in all sorts of directions.
Since paths which are ‘straight’ in Euclidean space are better since they involve less Euler steps and thus inference evaluations, ReFlowing a flow model leverages the fact that sampling transport paths from a trained model results in an average of paths that has been more ‘bundled’ together than the original data samples, and thus retraining on it results in a velocity model which can generate images in less Euler steps.
Formally, the velocity models for the original rectified flow, . And for one reflow procedure, where .
In general you can reflow as many times as you want but the benefits of this may fall off asymptotically, and usually just one reflow is fine.
 (image from 1)
(image from 1)