When you have models in the tens or hundreds of billions of parameters the model itself does not fit on a single GPU. What happens in practice is that the model is distributed as shards across GPUs (tensor parallelism) and during a forward or backward pass whenever the full layer is needed, intra-GPU communication via a gather or reduce joins the weight matrix together.
In this tutorial we’ll cover tensor parallelism, of which there are to main design patterns: column-parallel and row-parallel. For these examples we’ll assume we have 2 GPUs so WORLD = 2.
Column Parallel
no communication forward, all-reduce backward
The equation is (torch does matrix multiplication with the input on the left side). For column parallelism, the weight matrix is sharded along its columns W = [W_1 | W_2] and the input is not split.
There’s no communication in the forward pass because we can compute and such that Y = [XW_1 | XW_2] since the hidden dimension for the vector inner products within the matrix multiplies are preserved.
For backpropagation at each layer, the gradient with respect to the layer weight is computed and the gradient with respect to the layer input is computed. The former is for updating the layer and the latter is for the chain rule for the gradients for earlier layers.
Weight gradient
. As you can see from the diagram the weight update for can be computed locally.
Input gradient
. The sum of outer products, since the weight update to needs to be the same shape to the input.
Row Parallel
all-reduce forward, no communication backward
In row-parallelism the input that arrives has already been sharded along its columns. This means that the axis corresponding to the feature dimension has (in this case of WORLD = 2) been halved. In order to be able to do matrix multiplication, we’ll need to shard the weight matrix along the feature dimension so that the inner products of the rows and columns work. In this case, it means sharding along the rows of the weight matrix, as you can see in the diagram. After each GPU does a forward pass, each GPU contains a ‘layer’ of the final product, which must be summed in ‘sheets’ for the full prediction, .
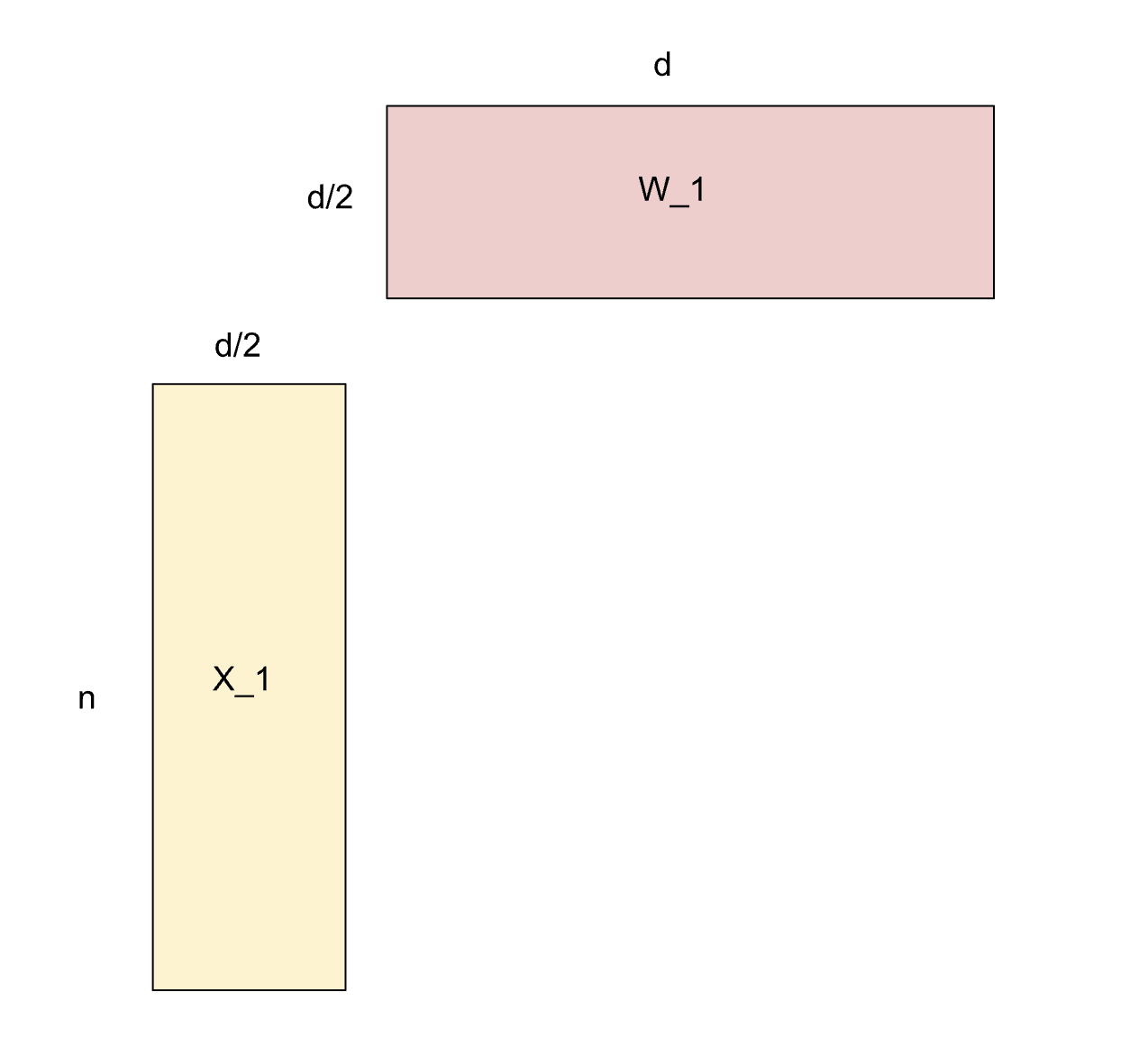
Weight gradient
Input gradient
As you can see, the backward passes do not require GPU communication.
CPU Parallelism
A way to learn how tensor parallelism works is to ‘handroll’ the parallelism, i.e. to manually shard the matrices and have torch.dist run multiprocessing over CPU, and numerically check that you’ve done the sharding correctly. Each architecture will have its own sharding layout. If you notice the main design pattern—column sharding results in a layer output that becomes a sharded input to the next layer, so the next layer has to be row sharded—you’ll see that the architecture is parallelized by repeated column and row shards.
In order to learn how this works, I decided to focus on the FLUX Klein 4B model, a multimodal diffusion transformer from Black Forest Labs (❤️🔥). Since it is decomposed into several repeated SingleStreamBlock and DoubleStreamBlock (the architecture processes image and text through separate mlps and attention in the double block phase before joining them together during the single stream phase), I decided to load a SingleStreamBlock and parallelize that to get the hang of things.
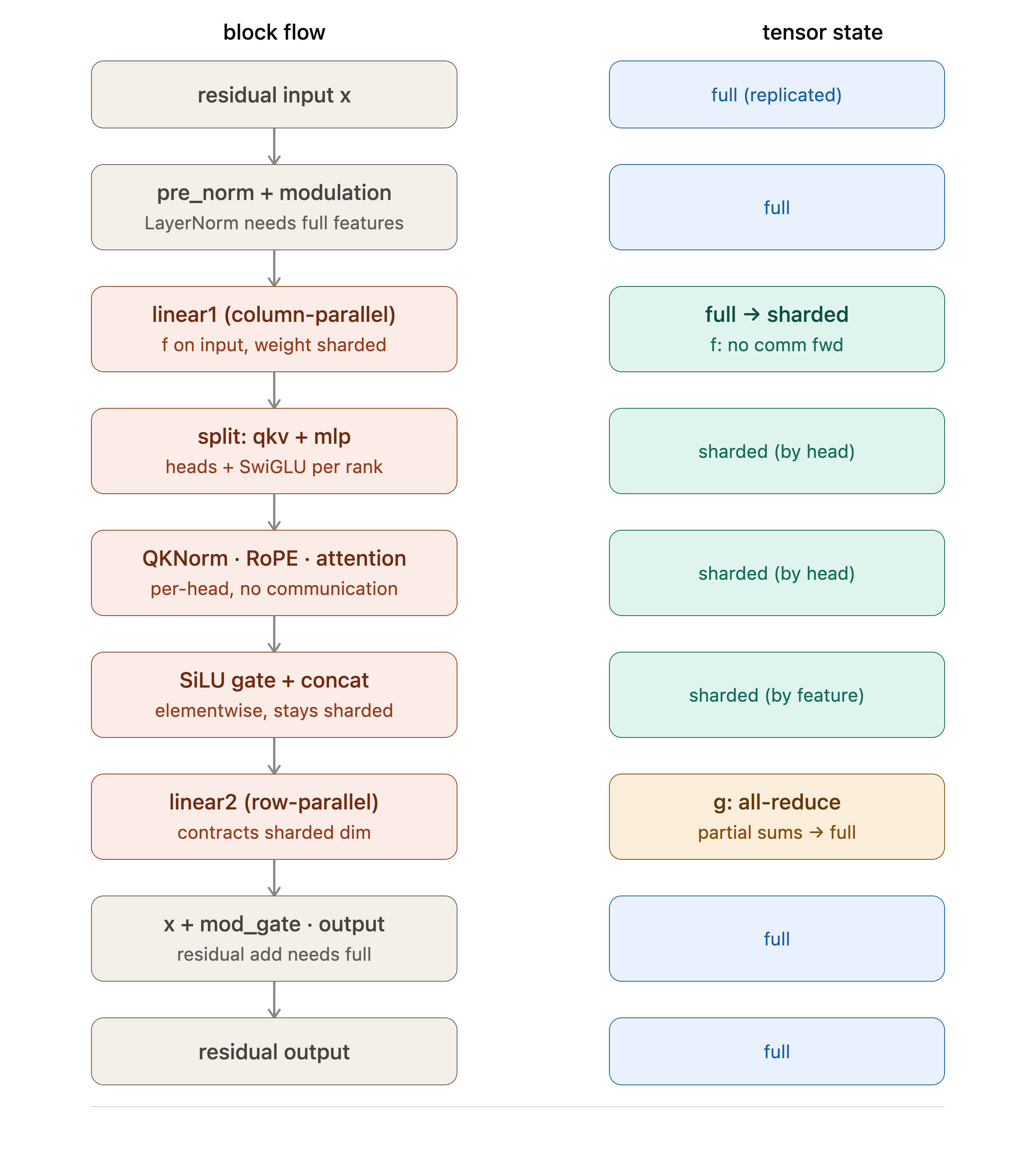
The single stream blocks are optimized so that the initial linear projection for the input X creates an output of shape (batch, seq_len, 3 * hidden + 2 * mlp_hidden). These form the matrices for the Q,K,V for attention and also the two layers of the mlp. This will be column sharded.
Whenever you are wondering whether an operation is ‘shard safe’, aka whether you can keep the input as sharded, just ask yourself ‘does this operation compute across the sharded dimension’?
Operations that need full
- Normalization across the feature dimension
- Residuals
x + f(x). Sincexis full,f(x)must be the same shape. - A matmul that contracts the sharded dimension (see diagram above), when each rank has only a partial sum, and you need an all reduce to complete it.
- Softmax
- Any reduction along the sharded axis—sum, mean, max over the feature dimension
- Reshapes that cross the shard boundary
Operations that do not need full
- Elementwise operations such as ReLU, SiLU, dropout, bias
- Per-head attention
- RoPE, when rotations are within
head_dim - QKNorm, aka RMS norm over
head_dim - Reshapes that don’t cross the shard boundary
- Slicing along a non sharded axis